VT-SCC:Visual-Text Semantic Deep Alignment via Multi-Modal Guidance for Unified Staple Crop Counting
Motivation & Overview
The automated quantification of crop reproductive organs anchors the advancement of high-throughput phenotyping, which is essential for accelerating genetic yield improvements and bolstering global nutritional security. However, the transition toward a universal counting paradigm is currently impeded by "species-specific isolation, " where models optimized for single domains fail to bridge the structural gap between diverse genotypes. Furthermore, the lack of distinct boundaries between targets and complex field backgrounds often leads to severe visual ambiguity in dense scenes. To address the adaptation challenges stemming from inconsistent target dimensions and morphological heterogeneity, we facilitate robust perception under drastic scale fluctuations by dynamically coordinating disparate visual signals. This objective is realized through our Scale-Adaptive Feature Aggregator (SAFA), which employs a parallel refinement architecture to disentangle multi-granular representations. Simultaneously, to counteract environmental interference, we introduce the Semantic-Guided Channel Modulator (SGCM). This module functions as a directable semantic filter, utilizing task-specific text prompts to recalibrate feature channels and isolate intended targets from cluttered background noise.

Figure 1:Paradigm comparisons and micro-motivation. (A) Siloed Paradigm: Specialized models with isolated knowledge and limited generalization. (B) Few-Shot Paradigm: Visual prompts vulnerable to background noise and interference. (C) Unified Framework: Robust multi-crop counting via multimodal semantic filtering. (D) Micro-Motivation: Transitioning from (1) species isolation and (2) multi-crop entanglement to (3) unified multi-scale alignment via semantic fields.
M2-Crop Benchmark Dataset
To surmount the scalability barriers posed by the segregation of existing plant counting data, we introduced the M2-Crop benchmark, designed to facilitate the learning of generic visual features across disconnected species domains. This multimodal collection consolidates 13, 474 images—originally from wheat, maize, rice, and soybean sources—into a cohesive detection framework that utilizes both text instructions and visual exemplars to clarify target identification in challenging field settings. Our spatial analysis using Normalized Nearest Neighbor Distance (NND) highlights the diversity of the dataset, which spans a wide spectrum of crowdedness—from tightly clustered soybean pods to spatially distributed rice panicles—thereby ensuring the framework is tested against varying degrees of occlusion and density.

Figure 2:Exemplary imagery from the M2-Crop multimodal benchmark. The grid provides a visual overview of the four target species—wheat, maize, soybean, and rice—across diverse field scenarios. These samples, integrated from four foundational datasets, illustrate the structural heterogeneity and background complexity inherent in unified agricultural counting.
Figure 3:Quantitative profiling of scene complexity across crop domains. (A) Instance count distribution: Boxplots delineate the variability and spread of target abundance within individual images; (B) Relative spatial density: Normalized Nearest Neighbor Distance (NND) analysis quantifies target crowdedness, highlighting the spectrum from highly occluded soybean clusters to spatially distributed rice panicles.
Framework Overview
The VT-SCC framework is a unified multimodal perception system designed to bridge the gap between abstract counting intentions and complex physical appearances. Built on a dual-stream architecture, the system employs a Swin Transformer backbone for multi-scale visual extraction and a BERT encoder to process category-specific instructions. This integrated framework facilitates a deep alignment between textual semantics and image data, enabling the model to transition from traditional "extract-and-match" paradigms to a more robust, directable counting process suitable for diverse agricultural scenarios.
Figure 4:Synergistic workflow of the VT-SCC unified framework. The architecture processes information through parallel streams: the visual branch extracts multi-scale features using a Swin Transformer, while the prompt branch synthesizes linguistic semantics and visual exemplars into task instructions. These signals are interleaved within the Deep Alignment Encoder, allowing the Cross-Modality Decoder to translate fused representations into precise instance localizations and the final count ŷ .
Scale-Adaptive Feature Aggregator (SAFA)
To address the multi-granularity challenges caused by significant variations in crop genotypes and imaging distances, we developed the Scale-Adaptive Feature Aggregator (SAFA). Standard backbones often produce scale-confused noise when target sizes fluctuate drastically. SAFA resolves this by utilizing a parallel decoupling mechanism with heterogeneous kernels to capture both intricate textures and broad structural contexts. A subsequent calibration unit predicts scale-aware weights to dynamically reweight these features, ensuring consistent perceptual stability regardless of the target's physical dimensions.
Figure 5:Internal components of the Scale-Adaptive Feature Aggregator (SAFA). To manage target dimension variability, the Decoupler maps the raw input Xin into a multi-granular feature space using heterogeneous convolutional kernels. Subsequently, the Calibrator computes global channel descriptors and generates scale-aware weights to dynamically amplify target-relevant signals, outputting a scale-robust representation Xenhanced via a residual connection.
Semantic-Guided Channel Modulator (SGCM)
To mitigate visual ambiguity in cluttered field environments—where targets like tassels or pods are often entangled with stems and foliage—we introduced the Semantic-Guided Channel Modulator (SGCM). This module functions as an intelligent semantic filter that leverages multimodal prompts to guide the model's focus. By calculating the interaction between prompt queries and global visual keys, SGCM selectively amplifies feature channels corresponding to the intended target while suppressing irrelevant environmental interference, thereby achieving high-precision discrimination in dense scenes.
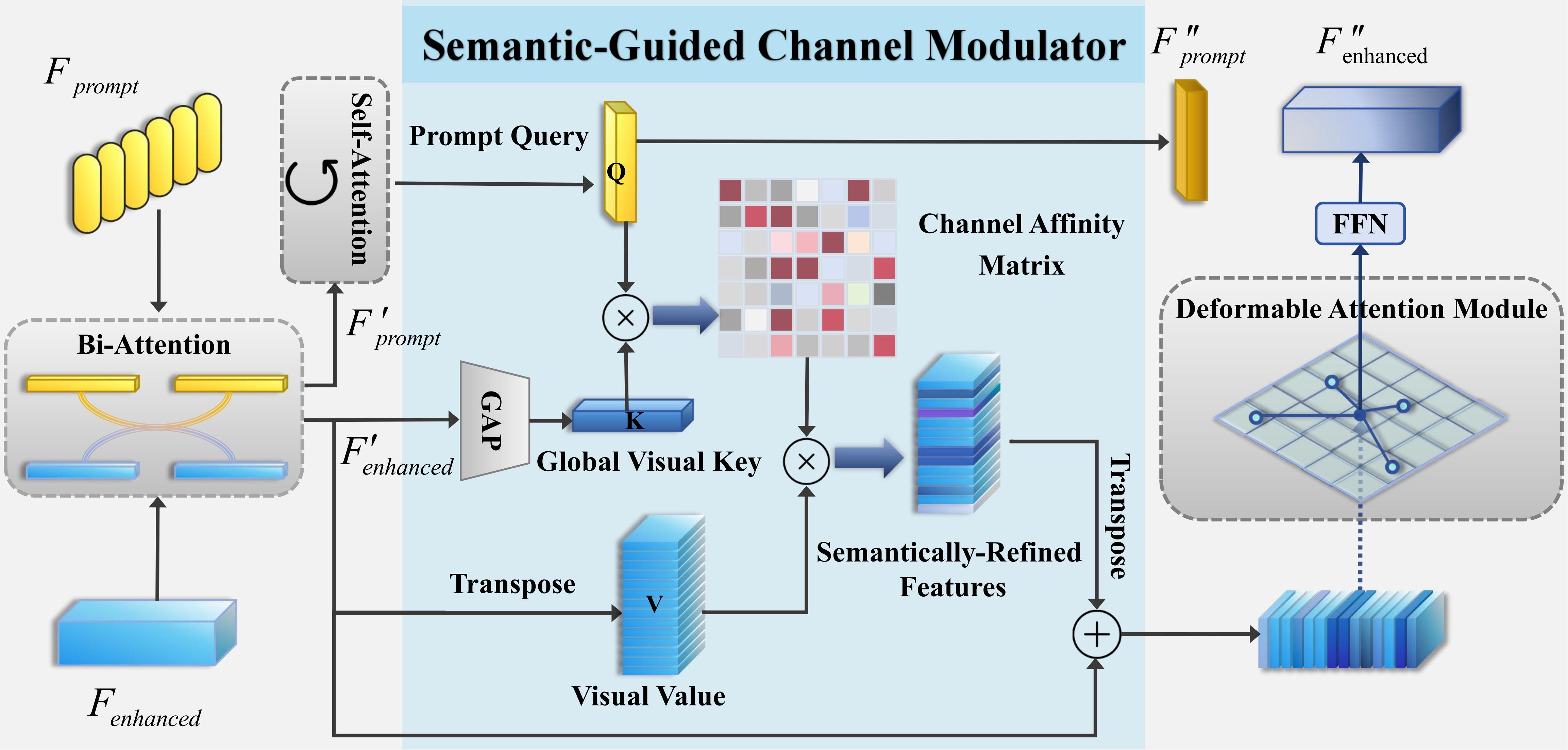
Figure 6:Semantic guidance mechanism within the Visual-Text Deep Alignment stage. This stage initiates multimodal correlation through Bi-Attention. The core modulator (SGCM) constructs a Channel Affinity Matrix by interacting the Prompt Query (Q) with the Global Visual Key (K), acting as a semantic filter to reshape the Visual Value (V). This process effectively suppresses background noise and delivers refined features to the Deformable Attention Module for precise signal activation.